/ local coding stack
Point your editor at your own box
Aim any OpenAI-compatible client at :8080/v1 —
chat, completions, and a dedicated coder slot. Your code never leaves the LAN,
and there's no per-token bill.
hal0 turns a Linux box — ideally a
Ryzen AI Max+ 395 — into a private,
OpenAI-compatible AI appliance: one /v1/*
API across every modality, with concurrent workloads the box manages for you.
One command installs the lot.
Aim any OpenAI-compatible client at :8080/v1 —
chat, completions, and a dedicated coder slot. Your code never leaves the LAN,
and there's no per-token bill.
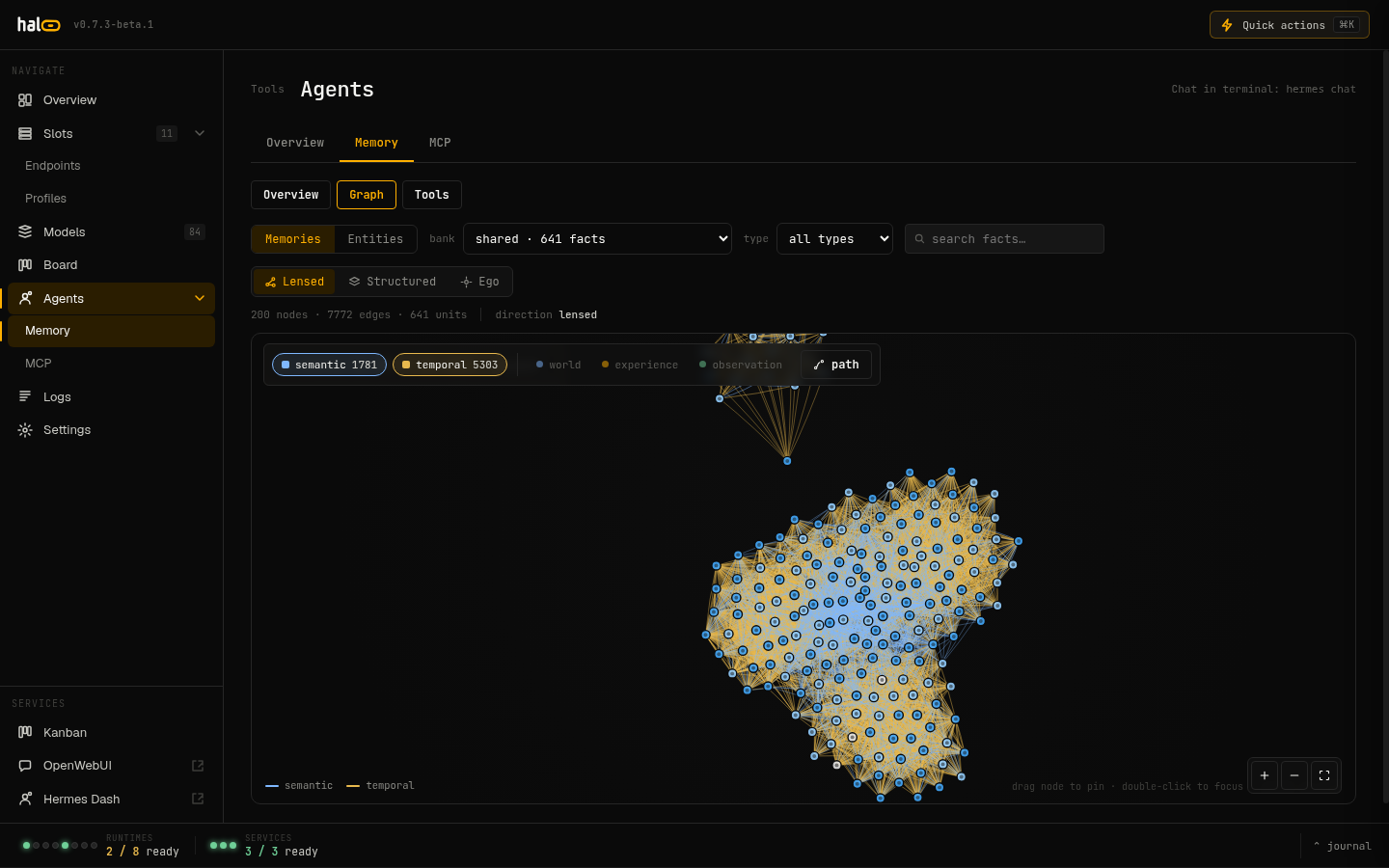
Embeddings, reranking, and a bundled agent with opt-in graph memory and MCP tools — a full RAG stack that runs on your hardware, not someone else's server.
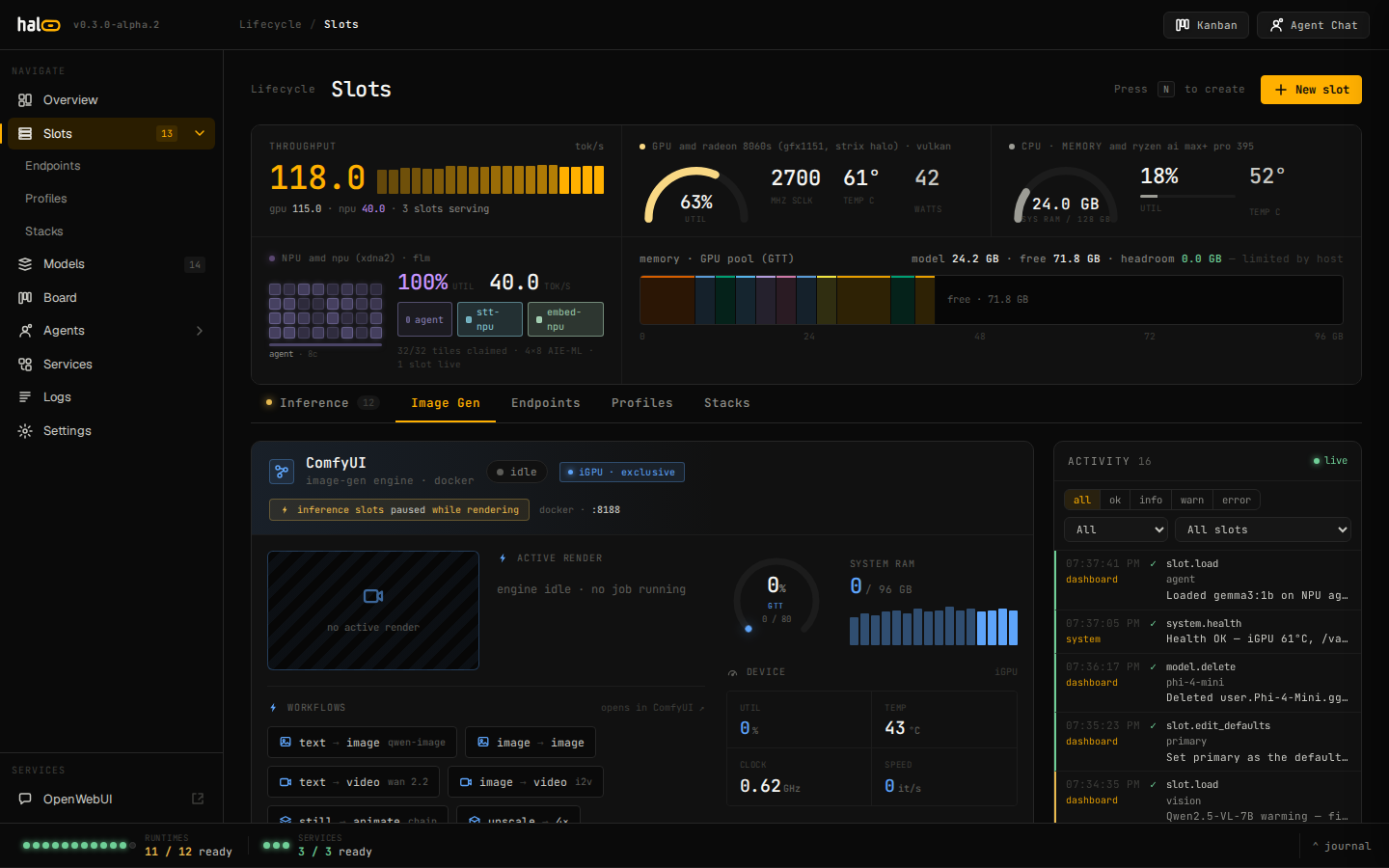
Transcription, text-to-speech, and local image generation behind the same API — STT on the XDNA NPU, TTS switchable between Kokoro (CPU) and Qwen3-TTS (GPU), ComfyUI on the iGPU, switched cleanly so they share the box.
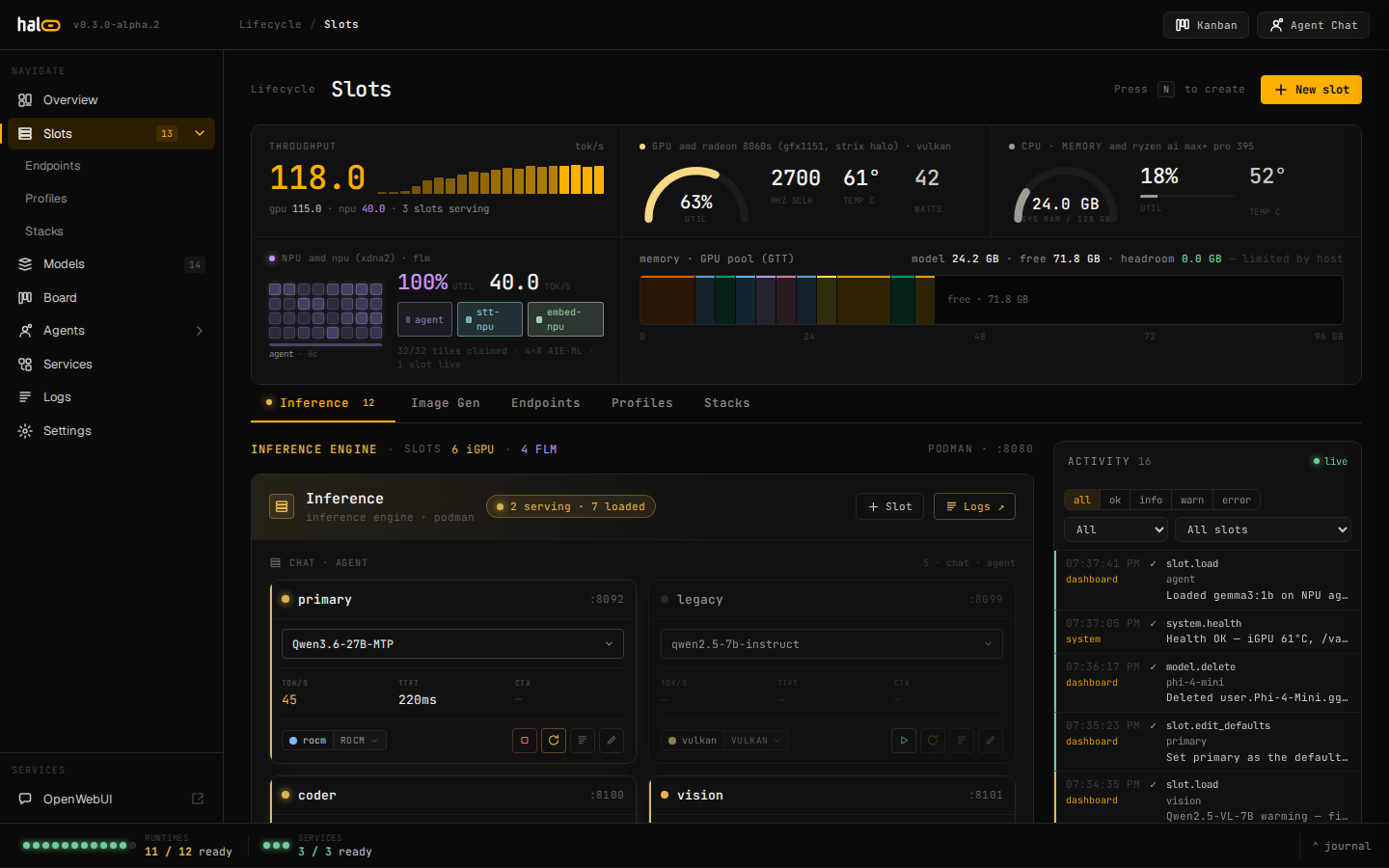
Every workload is a real systemd-managed slot with a typed lifecycle. The API surface covers chat and embed and rerank and STT and TTS and image gen. The dashboard is for operating the box — not for chatting with it.
chat · completions · embeddings · rerank · transcriptions · speech · images · models. Drop-in for any OpenAI SDK — point your client at :8080/v1 and go.
offline → pulling → starting → warming → ready → serving ↔ idle → unloading. Atomic transitions, persisted to state.json, streamed over SSE.
Registry-aware across local slots and external upstreams (OpenRouter, Anthropic, OpenAI, custom). Cold-cache prefetch coalesces a thundering herd into one HTTP call.
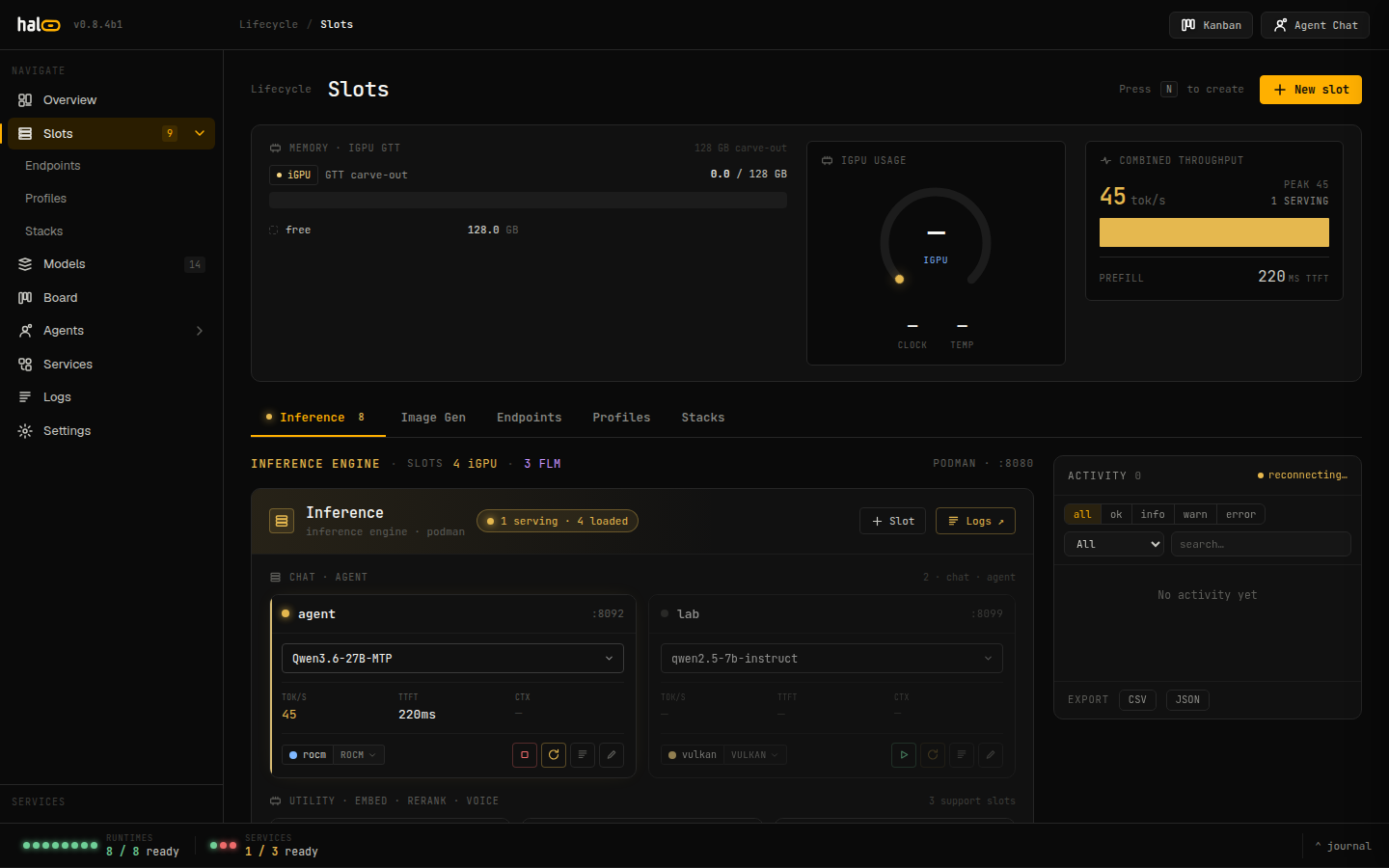
UMA pool on Strix Halo, real CPU/RAM/GPU on WSL2 / Proxmox / bare-metal. Slot-fit warnings size against the real unified pool, not a BAR carve-out.
hal0 update --channel stable|nightly. Verified tarballs swap a /usr/lib/hal0/current symlink. --rollback reverts atomically. Stable + nightly channels.
Plan a slot/model layout into a change set, apply it atomically with rollback, and converge the live slots against it — content-hash drift detection, plus export/import via a checksummed .hal0stack.json envelope.
Each provider is stateless — build_env() / start_cmd() / health() / infer().
No global state, no shared connection pool. The picker only advertises
a backend the slot can actually honour on your hardware.
The probe is UMA-aware on Strix Halo and falls back to portable parsers on every other host. The dashboard only labels memory "unified" when it actually is. Linux + systemd is the only hard requirement.
Sizes are published file sizes; the slot system takes a different model per slot whenever you change your mind. These are tuned for Strix Halo: A3B MoE models give 30–80B quality at ~3B token-gen speed, and an MTP head on MTP-enabled llama.cpp delivers a measured 1.4–2.4× decode speedup. FP4 is what makes them fit the unified pool — not what makes them fast.
Model ids are real, pull-able registry ids. Considering Apache-clean upgrades? Qwen-Image (beats FLUX on prompt + text rendering), Qwen3-Reranker-0.6B (pairs with the Qwen3 embedder), and Chatterbox-Turbo (zero-shot voice cloning) are easy pulls when you want them.
Slots survive hal0-api restarts. Embeddings, rerank,
STT, TTS, and image gen all sit behind the same
/v1/* surface. UMA-aware hardware probe and
slot-fit warnings are first-class — not a slash command in a chat window.
Competitor capabilities reflect each project's published docs as of June 2026 and move fast — treat this as a snapshot, not a live scorecard.
Slots, models, local image generation, graph memory, an agent task board, MCP, and logs — every surface in one React operator console. SSE-backed, dark by default. Real screenshots from a live hal0 instance.
Plus a Hermes agent that lives on the box, an Operator Board kanban wired to it, an MCP server + client, and a live XDNA NPU view — see the roadmap for everything shipped.
Hermes installs and bootstraps itself on first run — sandboxed under its own
user, prewired to the local /v1 API and your
MCP servers, with opt-in graph memory. Reach her from Telegram or Discord; she
chains tools for hours fully AFK and folds every run back into memory.
hal0-agent@hermes.service — own user, no new privileges.
No dates. Each themed row reads left-to-right: shipped,
in flight, exploring — the closer to the left, the closer it is to
running on your box. Tagged versions ship to
releases.hal0.dev within ~60s.
One command on a fresh Linux box. hal0 is pre-1.0 and moving fast — v0.9 is next — but it installs and runs the whole stack today.